अब तक कहानी: 1999 में, कैलिफ़ोर्निया स्थित Nvidia Corp. ने GeForce 256 नामक एक चिप को “दुनिया का पहला GPU” के रूप में विपणन किया। इसका उद्देश्य वीडियोगेम को बेहतर ढंग से चलाना और बेहतर दिखाना था। उसके बाद के 2.5 दशकों में, जीपीयू गेम और दृश्य प्रभावों की विवेकाधीन दुनिया से हटकर डिजिटल अर्थव्यवस्था के मुख्य बुनियादी ढांचे का हिस्सा बन गया है।
जीपीयू क्या है?
बहुत सरल शब्दों में कहें तो ग्राफिक्स प्रोसेसिंग यूनिट (जीपीयू) एक बेहद शक्तिशाली नंबर-क्रंचर है।
कम सरल शब्दों में: GPU एक प्रकार का कंप्यूटर प्रोसेसर है जो एक ही समय में कई सरल गणनाएँ करने के लिए बनाया गया है। दूसरी ओर, अधिक परिचित सेंट्रल प्रोसेसिंग यूनिट (सीपीयू) को कम संख्या में जटिल कार्यों को शीघ्रता से करने और कार्यों के बीच अच्छी तरह से स्विच करने के लिए बनाया गया है।
उदाहरण के लिए, कंप्यूटर स्क्रीन पर एक दृश्य खींचने के लिए, कंप्यूटर को हर सेकंड में कई बार लाखों पिक्सेल का रंग तय करना होगा। 1920 x 1080 स्क्रीन में प्रति फ्रेम 2.07 मिलियन पिक्सेल होते हैं। 60 प्रति सेकंड की फ़्रेम दर पर, आप 120 मिलियन पिक्सेल प्रति सेकंड से अधिक अपडेट कर रहे होंगे। प्रत्येक पिक्सेल का रंग प्रकाश, बनावट, छाया और वस्तु की ‘सामग्री’ पर भी निर्भर करेगा।
यह एक ऐसे कार्य का उदाहरण है जहां एक ही चरण को कई पिक्सेल के लिए बार-बार दोहराया जाता है – और जीपीयू को सीपीयू की तुलना में इसे बेहतर करने के लिए डिज़ाइन किया गया है।
कल्पना कीजिए कि आप एक शिक्षक हैं और आपको पूरे स्कूल की उत्तर पुस्तिकाएँ जाँचनी हैं। आप इसे कुछ दिनों में ख़त्म कर सकते हैं. लेकिन यदि आपके पास 99 अन्य शिक्षकों की सहायता है, तो प्रत्येक शिक्षक एक छोटा सा ढेर ले सकता है और आप सभी को एक घंटे में पूरा कर सकते हैं। एक GPU ऐसे सैकड़ों या हजारों श्रमिकों की तरह होता है, जिन्हें कोर कहा जाता है। जबकि प्रत्येक कोर सीपीयू कोर जितना शक्तिशाली नहीं होगा, जीपीयू में उनमें से कई हैं और इस प्रकार बड़े दोहराव वाले कार्यभार को तेजी से पूरा कर सकते हैं।
एक GPU जो करता है वह कैसे करता है?
जब कोई वीडियोगेम कोई दृश्य दिखाना चाहता है, तो यह GPU को त्रिकोण का उपयोग करके वर्णित वस्तुओं की एक सूची भेजता है (अधिकांश 3D मॉडल त्रिकोण में टूट जाते हैं)। फिर GPU रेंडरिंग पाइपलाइन नामक एक अनुक्रम चलाता है, जिसमें चार चरण होते हैं।
(मैं) वर्टेक्स प्रोसेसिंग: GPU पहले प्रत्येक त्रिभुज के शीर्षों को संसाधित करता है ताकि यह पता लगाया जा सके कि उन्हें स्क्रीन पर कहाँ दिखना चाहिए। यह वस्तुओं को घुमाने, उन्हें स्थानांतरित करने और कैमरे के परिप्रेक्ष्य को लागू करने के लिए मैट्रिक्स (संख्याओं की व्यवस्थित तालिकाओं की तरह) के साथ गणित का उपयोग करता है।
(ii) रेखांकन: जब जीपीयू को पता चल जाता है कि प्रत्येक त्रिकोण स्क्रीन पर कहां उतरता है, तो वह यह तय करके त्रिकोण को भरता है कि वह कौन से पिक्सेल को कवर करता है। यह चरण अनिवार्य रूप से स्क्रीन पर त्रिकोणों की ज्यामिति को पिक्सेल उम्मीदवारों में परिवर्तित करता है।
(iii) टुकड़ा या पिक्सेल छायांकन: प्रत्येक पिक्सेल जैसे टुकड़े के लिए, GPU अंतिम रंग निर्धारित करता है। यह किसी बनावट को देख सकता है (उदाहरण के लिए वस्तु पर लपेटी गई छवि), दीपक या सूर्य की दिशा के आधार पर प्रकाश की मात्रा की गणना कर सकता है, छाया लगा सकता है और प्रतिबिंब जैसे प्रभाव जोड़ सकता है।
(iv) फ़्रेम बफ़र पर लिखना: तैयार पिक्सेल रंग मेमोरी के एक क्षेत्र में लिखे जाते हैं जिसे फ्रेम बफर कहा जाता है। डिस्प्ले सिस्टम बफ़र को पढ़ता है और इसे स्क्रीन पर प्रस्तुत करता है।
शेडर्स नामक छोटे कंप्यूटर प्रोग्राम इन चरणों के लिए आवश्यक गणना करते हैं। GPU समान शेडर कोड को समानांतर में कई शीर्षों या कई पिक्सेल पर चलाता है।
प्रभावी रूप से जीपीयू बहुत बड़ी मात्रा में डेटा को पढ़ता और लिखता है – जिसमें 3डी मॉडल, बनावट और अंतिम छवि शामिल है – जल्दी से, यही कारण है कि कई जीपीयू की अपनी समर्पित मेमोरी होती है जिसे वीआरएएम कहा जाता है, जो वीडियो रैम के लिए संक्षिप्त है। वीआरएएम को उच्च बैंडविड्थ के लिए डिज़ाइन किया गया है, जिसका अर्थ है कि यह प्रति सेकंड बहुत सारे डेटा को अंदर और बाहर ले जा सकता है। फिर भी, समान डेटा लाने से बचने के लिए, GPU में कैश के रूप में छोटी, तेज़ मेमोरी और साझा मेमोरी की व्यवस्था भी होती है, जिसका लक्ष्य मेमोरी एक्सेस को बाधा बनने से रोकना है।

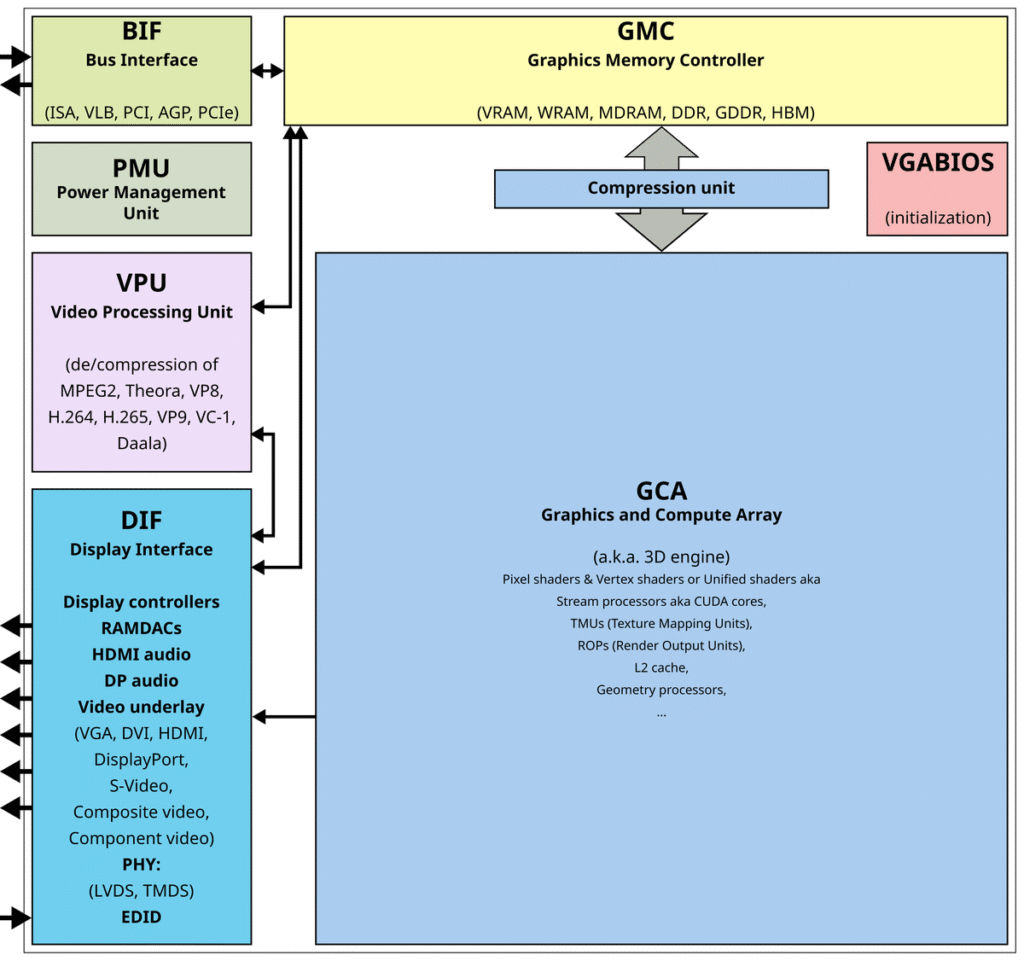
ग्राफ़िक्स कार्ड में पाए जाने वाले GPU का एक नकली आरेख। | फोटो साभार: सार्वजनिक डोमेन
ग्राफ़िक्स के बाहर के कई कार्यों में मशीन लर्निंग, इमेज प्रोसेसिंग और सिमुलेशन (जैसे कंप्यूटर मॉडल जो वर्षा का अनुकरण करते हैं) सहित संख्याओं के बड़े सरणी पर एक ही प्रकार की गणना करना शामिल है।
GPU कहाँ स्थित है?
चिप सिलिकॉन का एक सपाट टुकड़ा है, जिसे डाई कहा जाता है, जिसका एक निश्चित सतह क्षेत्र वर्ग मिमी में मापा जाता है।
कंप्यूटर में, GPU एक अलग परत नहीं है जो CPU के नीचे बैठती है; इसके बजाय यह सिर्फ एक और चिप, या चिप्स का सेट है, जो एक ही मदरबोर्ड पर या ग्राफिक्स कार्ड पर लगा होता है और हाई-स्पीड कनेक्शन के साथ सीपीयू से जुड़ा होता है।
यदि आपके कंप्यूटर में एक अलग ग्राफिक्स कार्ड है, तो जीपीयू को पकड़ने वाला डाई कार्ड के बीच में एक फ्लैट मेटल हीट सिंक के नीचे होगा, जो कई वीआरएएम चिप्स से घिरा होगा। और पूरा कार्ड मदरबोर्ड में प्लग हो जाएगा. वैकल्पिक रूप से, यदि आपके लैपटॉप या स्मार्टफोन में ‘एकीकृत ग्राफिक्स’ है, तो इसका मतलब संभवतः जीपीयू और सीपीयू एक ही स्थिति में हैं।
यह आधुनिक सिस्टम-ऑन-ए-चिप में आम है, जो मूल रूप से विभिन्न चिप प्रकारों वाले पैकेज होते हैं जो ऐतिहासिक रूप से अलग-अलग पैकेज में आते थे।
क्या जीपीयू सीपीयू से छोटे होते हैं?
कुछ मूलभूत रूप से छोटे प्रकार के इलेक्ट्रॉनिक्स का उपयोग करने के मामले में जीपीयू सीपीयू से छोटे नहीं हैं। वास्तव में, दोनों समान फैब्रिकेशन नोड्स से बने एक ही प्रकार के सिलिकॉन ट्रांजिस्टर का उपयोग करते हैं, उदाहरण के लिए 3-5 एनएम वर्ग। जीपीयू ट्रांजिस्टर का उपयोग करने के तरीके में भिन्न होते हैं, यानी उनके पास एक अलग माइक्रोआर्किटेक्चर होता है, जिसमें कितनी कंप्यूटिंग इकाइयां होती हैं, वे कैसे जुड़े होते हैं, वे निर्देश कैसे चलाते हैं, वे मेमोरी तक कैसे पहुंचते हैं, आदि (उदाहरण के लिए एनवीडिया एच100 में ‘एच’ हॉपर माइक्रोआर्किटेक्चर के लिए है।)
सीपीयू डिजाइनर डाई के अधिकांश क्षेत्र को जटिल नियंत्रण तर्क, कैश (सहायक मेमोरी), और सुविधाओं के लिए समर्पित करते हैं जो चिप के प्रदर्शन और तेजी से निर्णय लेने की क्षमता में सुधार करते हैं। दूसरी ओर एक जीपीयू कई दोहराए जाने वाले कंप्यूट ब्लॉकों और बहुत विस्तृत डेटा पथों पर अधिक क्षेत्र खर्च करेगा, साथ ही उन ब्लॉकों का समर्थन करने के लिए आवश्यक हार्डवेयर, जैसे मेमोरी कंट्रोलर, रजिस्टर फ़ाइलें, डिस्प्ले कंट्रोलर, सेंसर, ऑन-चिप नेटवर्क इत्यादि।
नतीजतन, जीपीयू – विशेष रूप से हाई-एंड वाले – में अक्सर कई सीपीयू की तुलना में अधिक कुल ट्रांजिस्टर होते हैं, और जरूरी नहीं कि वे प्रति वर्ग मिमी अधिक सघनता से पैक किए गए हों। वास्तव में, हाई-एंड जीपीयू अक्सर बहुत बड़े होते हैं। कुछ जीपीयू पैकेज डायनामिक रैम को जीपीयू डाई के बहुत करीब रखते हैं, जो उच्च बैंडविड्थ के साथ छोटे तारों का उपयोग करके जुड़ा होता है। अनिवार्य रूप से, घटकों की वास्तुकला को यह सुनिश्चित करने की आवश्यकता है कि GPU बड़ी मात्रा में डेटा को जल्दी से स्थानांतरित कर सके।
तंत्रिका नेटवर्क GPU का उपयोग क्यों करते हैं?
तंत्रिका नेटवर्क – कई परतों वाले गणितीय मॉडल जो डेटा से पैटर्न सीखते हैं और भविष्यवाणियां करते हैं – सीपीयू या जीपीयू पर चल सकते हैं, लेकिन इंजीनियर जीपीयू को पसंद करते हैं क्योंकि नेटवर्क समानांतर में कई कार्य चलाते हैं और बहुत सारे डेटा को स्थानांतरित करते हैं।
तंत्रिका नेटवर्क का गणित मैट्रिक्स और टेंसर संचालन के रूप में है। मैट्रिक्स ऑपरेशन पंक्तियों और स्तंभों जैसी संख्याओं के द्वि-आयामी ग्रिड पर गणना हैं; प्रत्येक ग्रिड में संख्याएँ एक ही वस्तु के विभिन्न गुणों का प्रतिनिधित्व कर सकती हैं। एक नया ग्रिड प्राप्त करने के लिए दो ग्रिडों को गुणा करना आवश्यक समस्या है। टेंसर संचालन एक ही विचार है लेकिन 3डी या 4डी सरणियों जैसे उच्च-आयामी ग्रिड का उपयोग करते हैं। यह तब उपयोगी होता है जब तंत्रिका नेटवर्क छवियों को संसाधित कर रहा होता है, उदाहरण के लिए, जिसमें एक वाक्य की तुलना में रुचि के अधिक गुण होते हैं।
 का मान a11b12 + a12b22 के बराबर है। इसी प्रकार, c33 (नीला-हरा वृत्त) का मान a31b13 + a32b23 के बराबर है।")
मैट्रिक्स गुणन में, का मान सी12 (लाल-पीला घेरा) के बराबर है ए11बी12 + ए12बी22. इसी प्रकार, का मूल्य सी33 (नीला-हरा वृत्त) के बराबर है ए31बी13 + ए32बी23. | फोटो साभार: लेकवर्क्स (CC BY-SA)
एक तंत्रिका नेटवर्क बार-बार मैट्रिक्स और टेंसर को जोड़ता और गुणा करता है। चूंकि यह गणितीय नियमों का एक ही सेट है, बस अलग-अलग संख्याओं पर लागू किया जाता है, एक जीपीयू के हजारों कोर इस काम के लिए बिल्कुल उपयुक्त हैं।
दूसरा, समकालीन तंत्रिका नेटवर्क में लाखों से अरबों पैरामीटर हो सकते हैं। (पैरामीटर नेटवर्क के अंदर सीखा गया वजन या पूर्वाग्रह मान है।) इसलिए गणित करने के अलावा, नेटवर्क को डेटा को पर्याप्त तेज़ी से स्थानांतरित करने में भी सक्षम होना चाहिए – और जीपीयू में बहुत अधिक मेमोरी बैंडविड्थ है।
कई जीपीयू में टेंसर कोर भी शामिल होते हैं, जो मैट्रिसेस को बहुत तेजी से बढ़ाने के लिए डिज़ाइन किए गए हैं। उदाहरण के लिए, NVIDIA H100 टेंसर कोर GPU FP16/BF16 नामक टेंसर ऑपरेशंस के प्रति सेकंड लगभग 1.9 क्वाड्रिलियन ऑपरेशंस निष्पादित कर सकता है।
वास्तव में, Google ने तंत्रिका नेटवर्क के लिए आवश्यक गणित को कुशलतापूर्वक चलाने के लिए टेन्सर प्रोसेसिंग यूनिट्स (टीपीयू) नामक चिप्स विकसित किए।

हरे रंग का बोर्ड जिस पर सब कुछ लगा हुआ है वह मुद्रित सर्किट बोर्ड है। बीच के पास एक ऊर्ध्वाधर स्तंभ में व्यवस्थित चार फ्लैट, चांदी धातु ब्लॉक तरल-ठंडा पैकेज हैं। हरी नली और रंगीन ट्यूब पैकेजों तक आने-जाने वाली शीतलक लाइनें हैं। प्रत्येक पैकेज में एक TPU v4 चिप होती है जो चार उच्च-बैंडविड्थ मेमोरी स्टैक से घिरी होती है। चार कनेक्टर बोर्ड के बाएं किनारे पर स्थित हैं। | फोटो साभार: arxiv:2304.01433
GPU कितनी ऊर्जा की खपत करते हैं?
आइए एक काल्पनिक उदाहरण का उपयोग करें जहां किसी व्यक्ति के लिए कुछ बीमारी के जोखिम की भविष्यवाणी करने के लिए एक तंत्रिका नेटवर्क को प्रशिक्षित करने के लिए चार जीपीयू का उपयोग किया जाता है (उम्र, बीएमआई, रक्त मार्कर, कुछ इतिहास के आधार पर)। फिर उसी नेटवर्क को उपयोग में लाया जाता है.
प्रत्येक GPU एक Nvidia A100 PCIe है, जिसकी बोर्ड शक्ति प्रशिक्षण के दौरान लगभग 250 W है। प्रशिक्षण के दौरान GPU का लगभग पूरी तरह से उपयोग किया जाता है। प्रशिक्षण की अवधि 12 घंटे है।
प्रशिक्षण के दौरान खपत की गई ऊर्जा 12 किलोवाट होगी और उपयोग के दौरान, लगभग 2 किलोवाट (यह मानते हुए कि केवल एक जीपीयू अनुमान प्रदान करता है)। सर्वर अपने सीपीयू, रैम, स्टोरेज, पंखे और नेटवर्किंग के लिए भी बिजली की खपत करेगा और कुछ बिजली खो जाएगी। इन आवश्यकताओं के लिए 30-60% GPU शक्ति जोड़ना सामान्य बात है। तो नेटवर्क को लगातार चलाने के लिए कुल खपत लगभग 6 kWh/दिन होगी।
यह पूर्ण कंप्रेसर शक्ति पर चार से छह घंटे के लिए एक एसी चलाने, लगभग तीन घंटे के लिए एक वॉटर हीटर या दिन में 10 घंटे के लिए 60 छोटे एलईडी बल्ब चलाने जैसा है।
क्या एनवीडिया का जीपीयू पर एकाधिकार है?
एनवीडिया का तकनीकी रूप से जीपीयू पर एकाधिकार नहीं है; कुछ बाज़ारों में इसका लगभग पूर्ण प्रभुत्व है और कृत्रिम बुद्धिमत्ता (एआई) कंप्यूटिंग प्लेटफ़ॉर्म में यह एक बहुत मजबूत बाज़ार शक्ति है।
व्यक्तिगत कंप्यूटरों में उपयोग के लिए बेचे जाने वाले अलग-अलग जीपीयू में, उद्योग ट्रैकर्स ने बताया है कि एनवीडिया के पास कम से कम 90% बाजार हिस्सेदारी है, जबकि एएमडी और इंटेल बाकी का अधिकांश हिस्सा बनाते हैं)। डेटा केंद्रों में उपयोग किए जाने वाले जीपीयू के लिए, एनवीडिया की स्थिति हार्डवेयर प्रदर्शन और आपूर्ति और सीयूडीए सॉफ्टवेयर पारिस्थितिकी तंत्र द्वारा मजबूत है।
CUDA एनवीडिया जीपीयू पर सामान्य प्रयोजन संगणना (जैसे सिग्नल को संसाधित करना या डेटा का विश्लेषण करना) चलाने के लिए एनवीडिया का सॉफ्टवेयर प्लेटफॉर्म है। परिणामस्वरूप, एनवीडिया जीपीयू का उपयोग बंद करने का मतलब सॉफ्टवेयर बदलना भी है, जो कंपनियां करना पसंद नहीं करती हैं। वास्तव में, कई खरीदार CUDA सॉफ़्टवेयर चलाने वाले एनवीडिया जीपीयू को प्रशिक्षण और बड़े पैमाने पर तंत्रिका नेटवर्क का उपयोग करने के लिए डिफ़ॉल्ट प्लेटफ़ॉर्म मानते हैं।
एकाधिकार की कानूनी परिभाषा इस बात पर निर्भर करती है कि क्या कोई फर्म कीमतों को नियंत्रित कर सकती है या प्रतिस्पर्धा को बाहर कर सकती है और क्या वह गैरकानूनी आचरण के माध्यम से उस शक्ति को बनाए रखती है। यही कारण है कि, उदाहरण के लिए, यूरोपीय नियामक इस बात की जांच कर रहे हैं कि क्या एनवीडिया ग्राहकों को लॉक करने के लिए अपने प्रभुत्व का उपयोग करता है, मुख्य रूप से जीपीयू की कीमतों को बांधने या छूट देने के द्वारा जब खरीदार एनवीडिया सॉफ्टवेयर या संबंधित घटक भी लेते हैं।
mukunth.v@thehindu.co.in



